In a previous blog we reviewed how to create and manage EKS Clusters on AWS. Apperati.io. In particular we discussed:
- How to use a simple tool from Weaveworks eksctl to setup and use EC2 nodes, network, security, and policies to get your cluster up.
- Providing access to the EKS cluster and how to use a easy but non-scalable configuration to provide access (modifying aws-auth configmap in the EKS cluster).
- Showcased Day 2 operations with respect to cost and utilization, security in AWS, and observability.
In this blog we will review some of the more scalable ways to manage access to the cluster.
Managing access to EKS clusters is a complex problem in AWS but also depends on how you have set up your organizations’ resources access policy and how the organization thinks about roles, groups and users. There is not simple or “cookie cutter” answer to properly setting up access policies and the organizational structure. Entire blog series can be written on this topic.
For purposes of simplicity, I assume the following in this blog:
- there is a concept of sub organizations in your organization which can be mapped to AWS IAM groups
- you have a concept of administrative and user roles in AWS.
- you have have or will be integrating AD into AWS for normalization with on-prem services and resources
- each user or a project (AWS IAM groups) has its own cluster vs namespace.
This last assumption is an important one. There are multiple theories and concepts about what is better in boundary conditions for K8S Clusters:
- Use the namespace as the boundary between users and/or projects. My personal belief - not a great strategy. This configuration leads you down setting up a massive cluster. You might as well have used a massive server or a mainframe.
- Use the cluster as a boundary between users and/or projects. This is fundamentally (in my view) a much better avenue. One of K8S value points is to make bare metal and VM more efficient. (like VMs made bare metal more efficient).
Hence this blog will be based on the premise that you are using a cluster boundary vs namespace boundary. It does not rule out the fact that different people accessing the cluster for a project might get different rights and resources (which can be segregated by namespace).
Managing users and access to EKS clusters
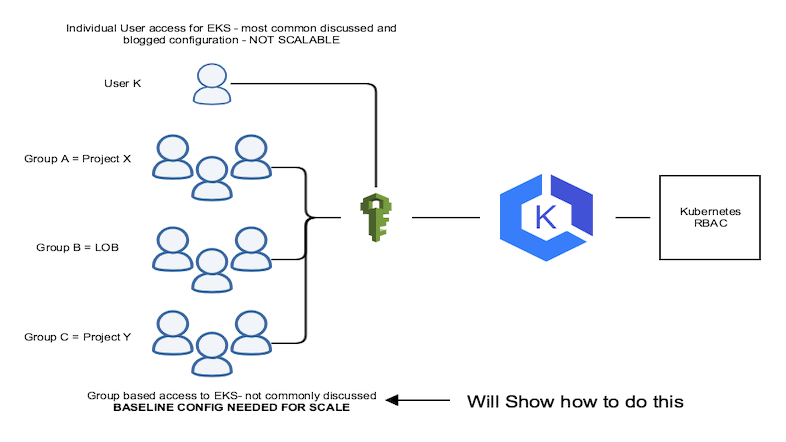
As per my previous blog Apperati.io, I identified the difficulties in scaling access to clusters on EKS. While its fairly simple to grant a user access to a cluster, the methods outlined by AWS are generally NOT scalable.
The main configuration normally described requires adding individual users from AWS IAM into the aws-auth file on the EKS cluster. Adding users to an EKS Cluster
What is the issue with this configuration?
- Setting up access requires EVERY EKS Cluster to have a list of “authorized” users and or roles.
- There is NO support for “group” authorization in the AWS authorization file on the EKS cluster
- Managing each cluster manually is NON-Scalable.
Bottomline: Creating, managing group based access in EKS clusters is convoluted
In order to build a scalable group authorization model with EKS clusters in AWS, I will first walk through some basic building blocks, which will help build a more scalable configuration:
- A review of Kubernetes authorization concepts with respect to roles in K8S and RABC. In particular we will concentrate on users vs service accounts in this blog to keep things simple.
- Details around setting up groups with the right permissions (authorization) for EKS access in AWS IAM and tying this back to the clusters. This will form the basis for any scalable configuration.
- How AWS IAM with EKS and Kubectl work in order to properly authenticate and authorize the user into the cluster.
Finally, I go through a high level review of a scalable solution - setting up access via AWS Directory Service in conjunction with AWS Organizations
Kubernetes Authorization through roles
In Kubernetes there are two basic types of users: service accounts and normal users. In the end these are still “users” in a Kubernetes cluster. In order to properly grant access to users in the cluster, we need to review several concepts in Kubernetes:
- role - a role contains rules that represent a set of permissions to different resources and is generally scoped to a namespace
- clusterRole - grants access to resources in the entire cluster
- RoleBinding - grants the permissions setup in the role to the user, set of users, group, service account
- ClusterRoleBinding - grants the permissions setup in the clusterRole to the user, set of users, group, service account
A full set of details and examples can be found Kubernetes RBAC.
Kubernetes has a set of predefined roles Kubernetes Predefined Roles. In any K8S cluster there are several default cluster roles that are important to understand before diving into cluster access:

As noted in the images, the basic default roles are fairly valuable and useable. As an example you can use the cluster-admin role and the basic-user too segregate users and admins of the cluster.
Or you can also define your own set to provide further control. For example:
- DevOps group in AWS IAM might be given cluster-admin role through system:master role bindings
- A project administrator could be given special right and a customer “admin” role would be defined in the cluster and assigned to a AWS IAM role for the administrator
- Define a specific role for all users in the cluster that need to read and write into the customer with restrictions against specific resources.
These roles would be defined in the a role.yaml config file in the EKS cluster.
# role.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ad-cluster-admins
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: ad-cluster-devs
rules:
- apiGroups: [""]
resources: ["services", "endpoints", "pods", "deployments", "ingress"]
verbs: ["get", "list", "watch", "create", "delete, "update"]
In the above YAML we defined three types of users, one for the cluster admin (who has unfeathered access into the cluster),another for the standard developer who has more restricted rights into the cluster, and a uber administrator (devops group)
Finally what about the devOps admin and mapping these roles to AWS IAM roles etc?
AWS EKS clusters all load with an authorization configmap called aws-auth located in the kube-system namespace:
ubuntu@ip-172-31-35-91:~$ kubectl get configmap --all-namespaces
NAMESPACE NAME DATA AGE
kube-system aws-auth 1 28d
kube-system coredns 1 28d
kube-system extension-apiserver-authentication 5 28d
kube-system kube-proxy 1 28d
This file helps map the users and roles defined in AWS IAM with Kubernetes roles and groups defined in the EKS cluster. This file also set the authorization (access) into the cluster.
Using the roles defined above here is a sample aws-auth file:
apiVersion: v1
data:
mapRoles: |
- rolearn: arn:aws:iam::XXXX:role/eksctl-fitcycle-nodegroup-ng-17dd-NodeInstanceRole-P22CZGF45HJU
username: system:node:{{EC2PrivateDNSName}}
groups:
- system:bootstrappers
- system:nodes
- rolearn: arn:aws:iam::XXXX:role/fitcycleEastAdmin
username: fitcycleEastAdmin
groups:
- system:masters
- rolearn: arn:aws:iam::XXXX:role/fitcycleDevCluster_Admin
username: adminuser:{{SessionName}}
groups:
- ad-cluster-admins
- rolearn: arn:aws:iam::XXXX:role/fitcycleDevCluster_User
username: devuser:{{SessionName}}
groups:
- ad-cluster-devs
kind: ConfigMap
metadata:
creationTimestamp: "2019-04-17T22:27:29Z"
name: aws-auth
namespace: kube-system
resourceVersion: "2083753"
selfLink: /api/v1/namespaces/kube-system/configmaps/aws-auth
uid: fc9e39e2-615f-11e9-901a-064ee69e86b2
As shown above the aws-auth file makes the following mappings:
- Maps AWS IAM role arn:aws:iam::XXXX:role/fitcycleEastAdmin to Kubernetes redefined role/group system:masters - this allows who ever has access to the fitcycleEastAdmin role to have full clusterAdmin right into the cluster. This role we will assign to our devOps group.
- Maps AWS IAM role arn:aws:iam::XXXX:role/fitcycleDevCluster_Admin to a custom Kubernetes group called ad-cluster-admins (for the project administrators)
- Maps AWS IAM role arn:aws:iam::XXXX:role/fitcycleDevCluster_User to a custom Kubernetes group called ad-cluster-devs (for the developers)
The two groups ad-cluster-admins and ad-cluster-devs are not defined anywhere in the Cluster. This YAML defines them for the first time.
Next we need to bind these two groups newly defined in the aws-auth file to the Kubernetes custom roles we defined earlier:
kubectl create clusterrolebinding project-admin --role ad-cluster-admins --group ad-cluster-admins
kubectl create clusterrolebinding project-devs --role ad-cluster-devs --group ad-cluster-devs
We’ve now created a mapping between Kubernetes roles and AWS IAM roles
Setting up AWS IAM groups for AWS EKS
Now that we have created the proper roles, groups and role mappings in the EKS cluster, we also need to set up the proper configuration in AWS IAM. As review three roles were mapped in AWS and the respective AWS groups they are mapped to:
- arn:aws:iam::XXXX:role/fitcycleEastAdmin –> mapped to DevOps groups in AWS IAM
- arn:aws:iam::XXXX:role/fitcycleDevCluster_Admin –> mapped to project admin groups in AWS IAM
- arn:aws:iam::XXXX:role/fitcycleDevCluster_User –> mapped to development clusters groups in AWS IAM
In order to set up the proper AWS IAM groups (as noted above) specific policies need to be configured allowing the group to “assume” the roles we have defined.
Note
“aws-auth” file in an EKS Cluster DOES NOT support “group” mapping from IAM
These issues are tracked here:
IAM Group addition to aws-auth
In order to work around this issue, we configure the following:
- An AWS IAM group will utilize sts:AssumeRole allowing anyone in the group to assume the role(s) we mentioned above.
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::XXXX:role/fitcycleEastAdmin"
}
}
- Setup roles with sts:GetCallerIdentity to allow aws-iam-authenticator to get the callers’ identity and complete authentication.
arn:aws:iam::XXXX:role/fitcycleEastAdmin configuration
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sts:GetCallerIdentity",
"Resource": "*"
}
]
}
How does with work? Its best to follow a flow:
Lets take ‘Bob’ as the user. He needs full access as a member of the devops team. Hence he must use the arn:aws:iam::XXXX:role/fitcycleEastAdmin role.
- ‘Bob’ utilizes kubectl with a configuration pointing to arn:aws:iam::XXXX:role/fitcycleEastAdmin role. (more on this later)
- kubectl + aws-iam-authenticator help authentication ‘Bob’. In order to do this, the role that ‘Bob’ is a part of (arn:aws:iam::XXXX:role/fitcycleEastAdmin) allows aws-iam-authenticator to get the callers identity (using sts:GetCallerIdentity) and authenticates ‘Bob’ and retrieves a token
- Once ‘Bob’ is authenticated into the cluster with the role arn:aws:iam::XXXX:role/fitcycleEastAdmin and because the role is also part of the “aws-auth” file ‘Bob’ is also authorized to be an administrator of the cluster with an Kubernetes role of “system:masters”
How is ‘Bob’ a part of arn:aws:iam::XXXX:role/fitcycleEastAdmin role considering AWS IAM groups are not allowed in “aws-auth.yaml”?
- ‘Bob’ is part of AWS group fitcycleEast
- AWS group fitcycleEast has a policy with an assume role of arn:aws:iam::XXXX:role/fitcycleEastAdmin
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::XXXX:role/fitcycleEastAdmin"
}
}
This policy then allows ‘Bob’ to implicitly use the arn:aws:iam::XXXX:role/fitcycleEastAdmin role, and thus have full system:masters access to the cluster.
Similarly roles roles for fitcycleDevCluster_Admin and fitcycleDevCluster_user can also be setup with policies that allow access to sts:AssumeRole attached to corresponding groups for each role - fitcycleEastProjectAdmin and fitcycleEastDev
Authenticating with kubectl and aws-iam-authenticator
In the previous section we walked through the configuration of the groups, roles, policies in AWS IAM. Essentially covered how authorization worked in the cluster. We also alluded to how authentication worked. In this section I will walk through how kubectl and aws-iam-authenticator work to help authenticate the user into AWS and the EKS cluster.
In any configuration with AWS EKS, users will always have a CLI setup with the following items configured:
- AWS CLI
- kubectl
- aws-iam-authenticator
These three interact in the following way.
Step one:
aws eks --region us-east-2 update-kubeconfig --name fitcycleEast
this pulls down a kube config file for kubectl
Step two:
you need to modify the config with the “-r” and - “arn:aws:iam::XXXX:role/fitcycleEastAdmin” lines. This is how ‘Bob’ asks to use the arn:aws:iam::XXXX:role/fitcycleEastAdmin role.
This allows the user to assume the role when authenticating with AWS.
Version: v1
clusters:
- cluster:
certificate-authority-data:XXX
server: https://XXXX.sk1.us-east-2.eks.amazonaws.com
name: arn:aws:eks:us-east-2:XXXXX:cluster/fitcycle
contexts:
- context:
cluster: arn:aws:eks:us-east-2:XXXX:cluster/fitcycle
user: arn:aws:eks:us-east-2:XXXX:cluster/fitcycle
name: arn:aws:eks:us-east-2:XXXX:cluster/fitcycle
current-context: arn:aws:eks:us-east-2:XXXX:cluster/fitcycle
kind: Config
preferences: {}
users:
- name: arn:aws:eks:us-east-2:XXXX:cluster/fitcycle
user:
exec:
apiVersion: client.authentication.k8s.io/v1alpha1
args:
- token
- -i
- fitcycle
- "-r"
- "arn:aws:iam::XXXX:role/fitcycleEastAdmin"
command: aws-iam-authenticator
Step three:
check to see if you can access the cluster
ubuntu@ip-172-31-35-91:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-29-140.us-east-2.compute.internal Ready <none> 25d v1.11.5
ip-192-168-37-105.us-east-2.compute.internal Ready <none> 25d v1.11.5
ip-192-168-72-126.us-east-2.compute.internal Ready <none> 25d v1.11.5
So what happened in Step three?
When ‘Bob’ uses kubectl get nodes, kubectl calls aws-iam-authenticator with the appropriate role (arn:aws:iam::XXXX:role/fitcycleEastAdmin) the following happens:
- aws-iam-authenticator uses the “-r” to assume the role arn:aws:iam::XXXX:role/fitcycleEastAdmin, which allows aws-iam-authenticator to gets ‘Bob’s identity to help authenticate with AWS (using sts:GetCallerIdentity). A token is received.
- kubectl uses this token along with the cluster api keys to access the cluster
- the EKS cluster then recognizes the role arn:aws:iam::XXXX:role/fitcycleEastAdmin from the kubectl call, and recognizes that the role has access rights as ‘system:master’ and authorizes
kubectl get nodes
A great detailed write up is here: https://itnext.io/how-does-client-authentication-work-on-amazon-eks-c4f2b90d943b#609a
The end to end flow is shown here:
Scalable user access using AD
The ideal way to actually scale access to the EKS Cluster is through integration with AD using AWS Directory Service in conjunction with AWS IAM and AWS Organizations.
The solution is outlined here:
If you walk through the solution in the linked blog, you will see that the concepts and configurations outlined in my previous sections are used (almost identical) to what is outlined in the blog.
The only difference is that my configurations will allow you to utilize AWS IAM + Kubernetes RBAC to manage access, while the AWS documentation adds in AWS Directory Service and AWS Organizations
Let’s review the AD based solution:
- Assume you have setup AWS Organizations, and AWS Managed Microsoft AD.
- Set up admin and user group in AD (similar to the configuration I outlined in the section above BUT these are setup as part of AD as groups in AD)
- Assign a permission set for each of the groups with sts:AssumeRole
- Create the roles in K8S - the EKS cluster (exactly as I specified above)
- Add the AD roles created in AWS into the aws-auth file and create appropriate groups (similar to our step above)
- bind the Kubernetes groups to the customer roles defined in step 4
- Modify the kubeconfig with the -r parameter I described above (with the role you want to assume for the user)
- GO
This configuration makes it easier for you to scale and also tie AWS Managed Microsoft AD back to your on-prem AD version.
Conclusion
We’ve shown in this blog the following:
- A review of Kubernetes authorization concepts with respect to roles in K8S and RABC. In particular we will concentrate on users vs service accounts in this blog to keep things simple.
- Details around setting up groups with the right permissions (authorization) for EKS access in AWS IAM and tying this back to the clusters. This will form the basis for any scalable configuration.
- How AWS IAM with EKS and Kubectl work in order to properly authenticate and authorize the user into the cluster.
Finally, I went through a high level review of a scalable solution - setting up access via AWS Directory Service in conjunction with AWS Organizations
Hopefully this gave you a better understanding of the basic concepts needed to manage AWS IAM group based access into AWS EKS clusters.
With these basics you can then properly setup the strategy for access to different projects/groups etc.