As more and more applications convert to cloud native with Kubernetes as a normalizing layer the ability to have portability between public clouds also becomes easier. Theoretically, the app can now move easily between AWS/Azure/GCP. However, a couple of issues are always in the back of developer’s minds:
- Do I connect to cloud services like ML/AI, DevOps tool chains, DBs, Storage, etc? This might lock me in.
- Should I roll my own database or use a cloud services like CosmosDB, Azure Postgres DB, etc.? I will cover the second question in this blog. This decision point revolves between implementing a self-managed or a fully managed database.
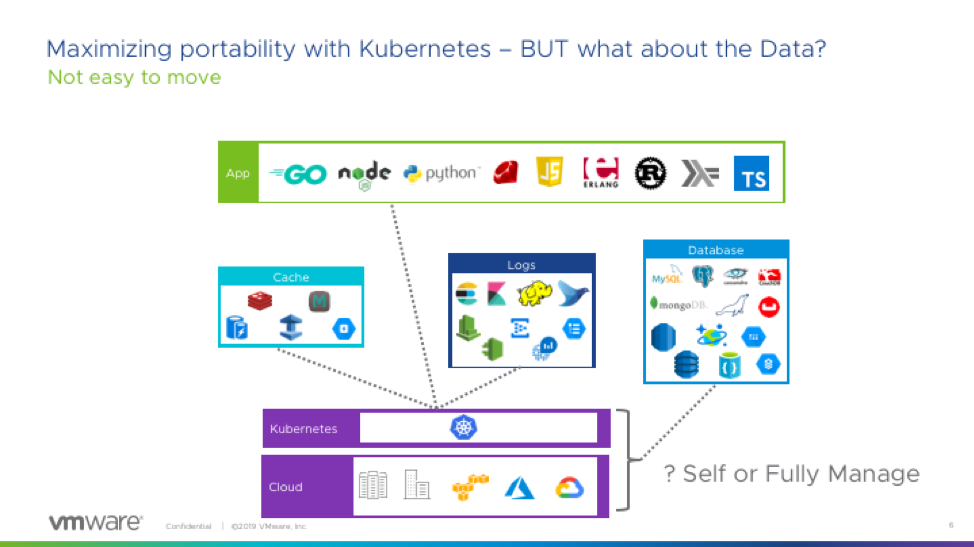
Before we proceed let’s understand the definitions of self/fully managed in the context of this blog.
-
Self managed database – is defined as an implementation of a specific database configuration in which the DevOps admin managed the entire lifecycle of the database. This includes bringing up the database with the appropriate configuration (including HA, encryption, security, etc), managing backups, upgrades, security patching, etc. This is fairly complex and requires expertise, but may be necessary given the business requirements. Requirements such as GDPR, auditing, secured storage, etc.
-
Fully managed database – is defined as consumption of a database offered through a managed service provider (i.e. Azure) or IT even. The DevOps admin no longer has to worry about any configuration, backups, upgrades, or security patching. They do worry about properly setting guardrails on the database. Who or what has access and to what they have access. For the purposes of this blog we will consider Hyperscaler services like Cosmos DB or Azure Postgres DB.
Decision points:
Multiple factors can be considered in making this decision. I’ll cover a few of these decision points (not comprehensive) and review how it applies to an example application.
Specific applications could have dependencies that cannot be provided on specific database types and/or database versions. A perfect example is a financial application which uses an older version of a DB such as Ingress DB, which isn’t even available as a managed service. The operations team would have to roll out Ingress DB on Azure compute nodes, and manage the entire lifecycle. Another healthcare DB has requirements to use an older version of Postgres that cannot be upgraded due to the simple fact that developers (and/or funds) are not available to upgrade the application code to use newer versions of Postgres. In these examples, the easy and obvious decision would be to roll your own DB on the hyperscaler environment.
Database redundancy and high availability are another factor. While potentially simple for small applications and dev/test environments, the configuration can become onerous when dealing with a scaled application. Hence in production envionments with strict availability requirements, using a managed service such as Azure Postgres DB is wise. High availability is supported as default. Data is automatically replicated into Azure storage when a transaction is committed. Hence if a node goes down, Azure automatically brings up a new nodes and re-attaches the storage. Configuring anything similar in a self-managed database requires advanced knowledge and skills.
Whether to save primary storage space (tier 1) or ensure disaster recovery, an ability to consistently backup the database and potentially restore is generally a business requirement. Building out the proper backup and restoral mechanisms for a self-managed database requires full knowledge of the backend and storage. Several parts of the operations that need to be designed include:
-
Setting up and configuring initial and scalable back end storage in multiple tiers – where the first tier is potentially cache and last tier being “cold” backup storage.
-
Understanding and setting up how to restore and recover data as quickly as possible.
-
When and how to scale the storage
-
etc
Hence, this is complex but it can be built and maintained with substantial operations and capital cost. However, using a managed service such as Azure Postgres DB, these capabilities are easily available as a configuration option. Not only can data be backed up but the frequency of backup (weekly, daily), local vs geo redundancy, type of backup storage can all be selected. In addition, other features like encryption are base line default capabilities. Restoral is also easy, and the precise point in time can also be selected to restore.
Another major concern with databases is compliance. The standard PCI, HIPPAA, etc compliance requirements can be meet on both self or fully managed databases. As these require specific implementations of tenancy, encryption, redundancy, etc. However, issues such as geo-bounding (storing data in specific geos), are not truly database centric but rather application centric. The application is required to essentially “route” the data to the proper geo-storage. Many businesses seriously consider using a self-managed (mainly on-prem) implementation, due to an obvious ability to control the implementation and meet the requirements. However, a fully managed service on a hyperscaler generally has a long set of certifications that ensure the storage meet PCI, HIPPA, etc requirements. Enabling to get closer to meeting your compliance needs faster and easier.
Operational expertise is a big factor in this decision. Many businesses don’t have the database expertise to deploy, configure, scale, and maintain these databases. Using Kubernetes adds even more complexity to the puzzle. This complexity is realized because of the need to manage kubernetes it self, and the interconnections with storage. While the K8S community is working on things like operators to make it simple. The operations personal still has to determine how to setup and manage the storage component that K8S connects to. Hence there is still a need to have significant expertise in infrastructure. Instead, a fully managed service with secure connections reduces the need for database expertise (Kubernetes or not) and infrastructure expertise.
Finally, the issue of scale is a large consideration when it comes to self-managed vs fully managed databases. Scaling requires a more complex implementation leading to more nodes, storage, security, etc. Many businesses might have the expertise to manage the scale, but many do not. Fully managed services like Azure Postgres DB allow incremental increases in the database capacity through the addition of new nodes when needed with a selection of varied costs, cores, storage, and connections.
While I covered a few of the more common factors above, there are many more factors. The following table iterates through a more complete list:
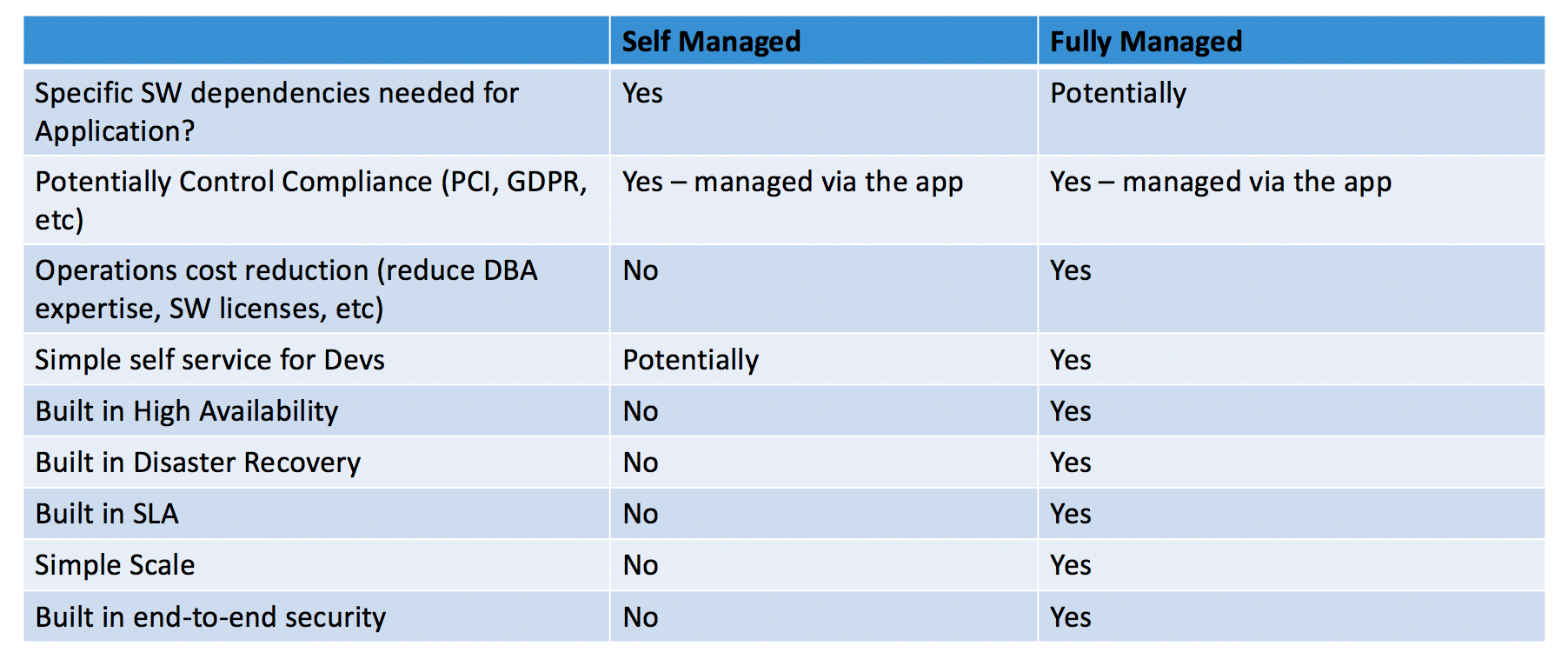
While the obvious choice per the table is using a fully managed database, its truly dependent on business requirements and cost. In many cases self-managed databases are chosen for various political and business decisions, but the truly obvious choice is a hyperscaler based database service.
Example application:
As we started in this blog, many applications are becoming orchestrated via Kubernetes. While the Kubernetes based application can migrate from cloud to cloud, the database can be implemented, secured, scaled, and maintained in one cloud with a secure potentially low latency connection.
We built a sample application, called Acme Fitness, which is an e-commerce application that has several services and databases and is deployed with Kubernetes.
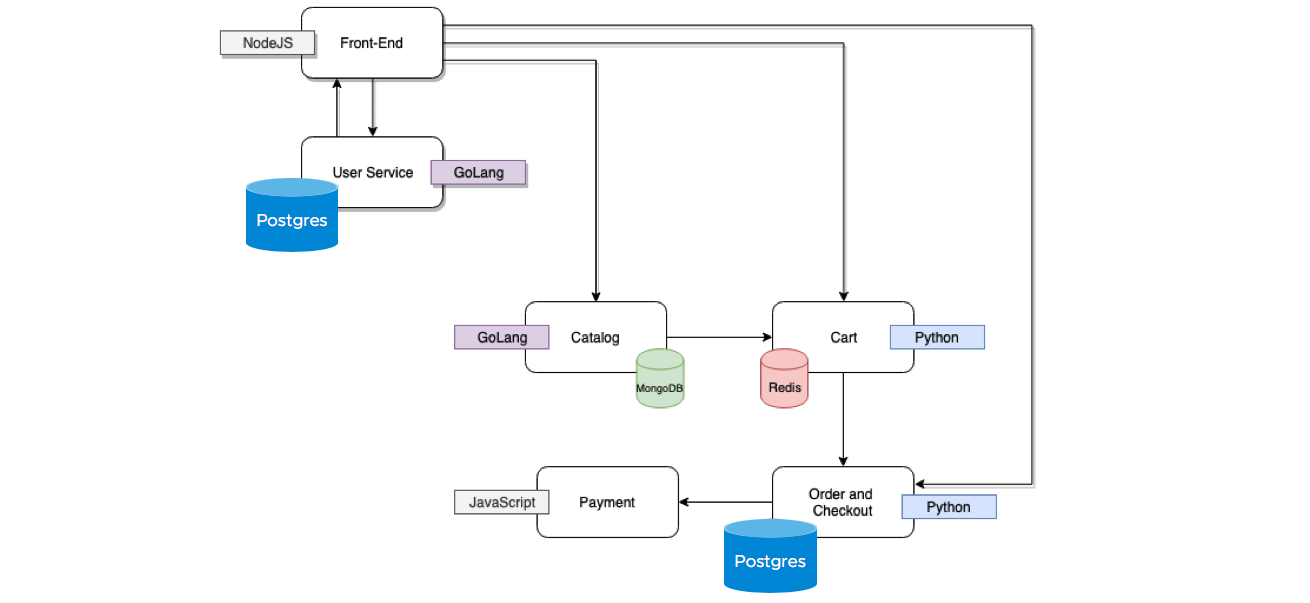
Let’s review the application’s databases, what was used and why from a devOps perspective.
-
User service – stores users profiles and passwords. This data is long term and using a DB such as Postgres is viable. However the number of users will most likely grow if ACMEfitness is successful, hence using Azure Postgres DB is a viable option.
-
Catalog service – requires a large number of catalog items which includes catalog item details as well as images for each item. Most likely won’t grow as much as the user service, since the catalog is limited to fitness products. For now the team has selected to implement MongoDB on Azure compute. They could have chosen to use Azure Cosmos DB which is compatible with Mongo DB. They can always move this over when it becomes viable.
-
Cart Service – is where the users “Cart” is stored and this information is ephemeral until the user “checks” out. Until then this will change and or even be completely be deleted. The application team has chosen to implement a local Redis service to support this.
-
Order Service – is where ALL transactions, including all the items as part of the transaction are kept. The obvious choice here is a database like Postgres. However, compared to the user or catalog databases, this database will scale heavily. Hence using a database service such as Azure Postgres Citus becomes compelling.
All the databases have different requirements and different implementations, 2 self-managed DBs and 2 fully managed DBs. As the application evolves and hopefully the business grows these requirements might change. Monitoring and understanding these needs is important to ensure the proper database implementation is available for the application.
Conclusion:
Hopefully the description above provides an understanding of when to pick or not to pick using a fully managed database from a hyperscaler like AWS, Azure, GCP or other cloud provided options. The basic goal in using the fully managed database service is to avoid becoming an expert in databases or infrastructure and concentrate on your business by concentrating on your application, its delivery, and the quality of the application’s value to your end customer.
While a hyperscaler based service could be more expensive than rolling your own, the cost of operations, maintaining the expertise, and potential down time due to mis-configurations etc is not always considered appropriately. Hence the innovation, acceleration in business, and offset of expertise more than makes up for any potential capital cost from the hyperscalers.
In the end there is no right or wrong answer, but hopefully the summary provided important points to consider in deciding what to choose when building a stateful kubernetes based application in the cloud.
Future:
In the next blog we will explore in detail how the Orders database was:
-
Deployed using Azure’s Open Service Broker capability through VMware Bitnami
-
How the Order code is structured to handle a scalable Postgres database such as Azure Citus
-
How the deployment scales
-
The important aspects of the database – Azure Citus, and why it was picked.