
When I began working with Kubernetes, I deployed simple applications from tutorials with very basic YAML manifests into my clusters. As my comfort level with the technology grew, I wanted to deploy more complex applications to continue learning.
After creating some YAML manifests from scratch, I felt things were moving too slowly, and I enlisted a common aid for new Kubernetes users, Helm. Helm interested me because it was billed as “The Package Manager for Kubernetes” which fit my needs at the time. As my comfort level with Kubernetes grew, I’ve also explored the use of Kubernetes operators to help deploy and manage the operational lifecycle of applications. I’ll explore that framework below as well, and give some thoughts on how the two compare.
Does Kubernetes need a Package Manager?
In a word, no. But we (humans) tend to struggle with YAML manifests which can be hundreds or thousands of lines long. On the Apperati authors, we don’t want to maintain manifests for every permutation of an application or manage its versioning and lifecycle. We’d much rather offload those tasks to a reliable (and automatable) tool with the flexibility to modify parameters for me when instructed to do so.
Within operating systems, these functions are typically handled by package managers. Common examples of package managers include tools such as RPM, Apt, and Homebrew. While an application exposed through a package manager can also be installed manually, many have come to rely on the convenience and simplicity of deploying new applications via a single interface.
Applications in kubernetes are frequently composed of a set of microservices, individual pieces of software communicating via lightweight methods (such as a REST API). In order to describe the interactions between these services, a set of parameters is typically defined as they are deployed. The complexity of interconnecting and operating these services grows as their number increases, and this complexity is reflected in the required set of application parameters. For more information on how services interact with each other in Kubernetes, please see my previous post. Packaging is a method for managing this complexity and tracking variations across versions and environments.
What is Helm?
Helm is an open source project which helps users find, share, and deploy software onto Kubernetes clusters. Helm is maintained by the Cloud Native Computing Foundation (CNCF) in collaboration with its contributor community and three companies; Microsoft, Google, and Bitnami (acquired by VMware).
Central Concepts
Charts are the package format used by Helm. They define a set of resources to be deployed to a Kubernetes cluster. Functionally, charts are comparable to an APT dpkg or Homebrew formula.
Repositories are locations where charts can be accumulated and distributed. They’re similar in function to Apt or RPM repositories.
Releases represent an instance of the contents of a chart running in a Kubernetes cluster. If a chart is installed multiple times into the same Kubernetes cluster, it will be given a unique release with a corresponding name each time.
To summarize, Helm is used to install charts into Kubernetes clusters. The installation of a chart creates a release. To locate Helm charts to deploy, one would search a Helm chart repository.
Helm Architecture
The architecture of the current version of Helm (Helm 2) consists of two major components; the Helm client and the Tiller server.
The Helm client is a command-line interface for users with three functions:
- Developing Helm charts
- Managing repositories
- Communicating with Tiller
The Tiller server is runs within a Kubernetes cluster and interacts directly with the Kubernetes API server. Tiller is responsible for:
- Receiving requests from the Helm Client
- Constructing a release from a Helm chart and configuration
- Deploying charts to Kubernetes and monitoring the state of the resulting release
- Managing the lifecycle of a release
Visually, the architecture looks like this:
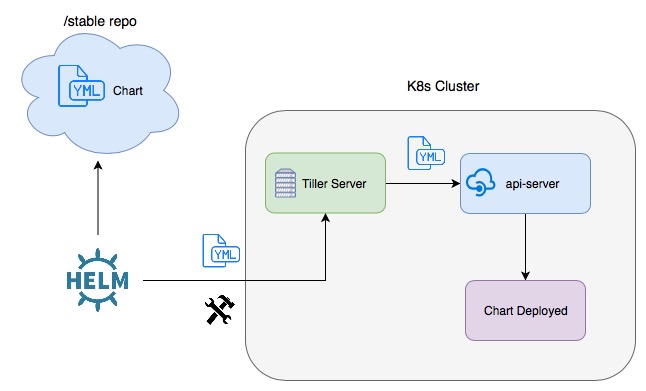
In general, most of the Helm client’s tasks are related to charts, while Tiller is mostly concerned with releases. This architecture is in the midst of undergoing some changes as Helm transitions from its version 2 into version 3. In Helm 3, Tiller will be removed, and the Helm client library will communicate directly with the Kubernetes API server. This change has been enabled by advancements in role-based access control (RBAC) in modern versions of Kubernetes. More information on Helm’s architectural transition may be found here.
What are Operators?
The Operator Framework for Kubernetes publicly dates to this 2016 CoreOS blog post. It represents another common methodology for packaging Kubernetes services and applications. To quote the blog post:
An Operator is an application-specific controller that extends the Kubernetes API to create, configure, and manage instances of complex stateful applications on behalf of a Kubernetes user. It builds upon the basic Kubernetes resource and controller concepts but includes domain or application-specific knowledge to automate common tasks.
Operators implement both Day 0 (installation/configuration) and Day 2(configuration modification/component lifecycle) tasks into a piece of software running within a Kubernetes cluster. This is accomplished through Kubernetes-native concepts; controllers, custom resource definitions (CRDs), and API extensions. This model allows users to treat a complex application as a single object rather than a set of Kubernetes primitives.
How does an Operator Work?
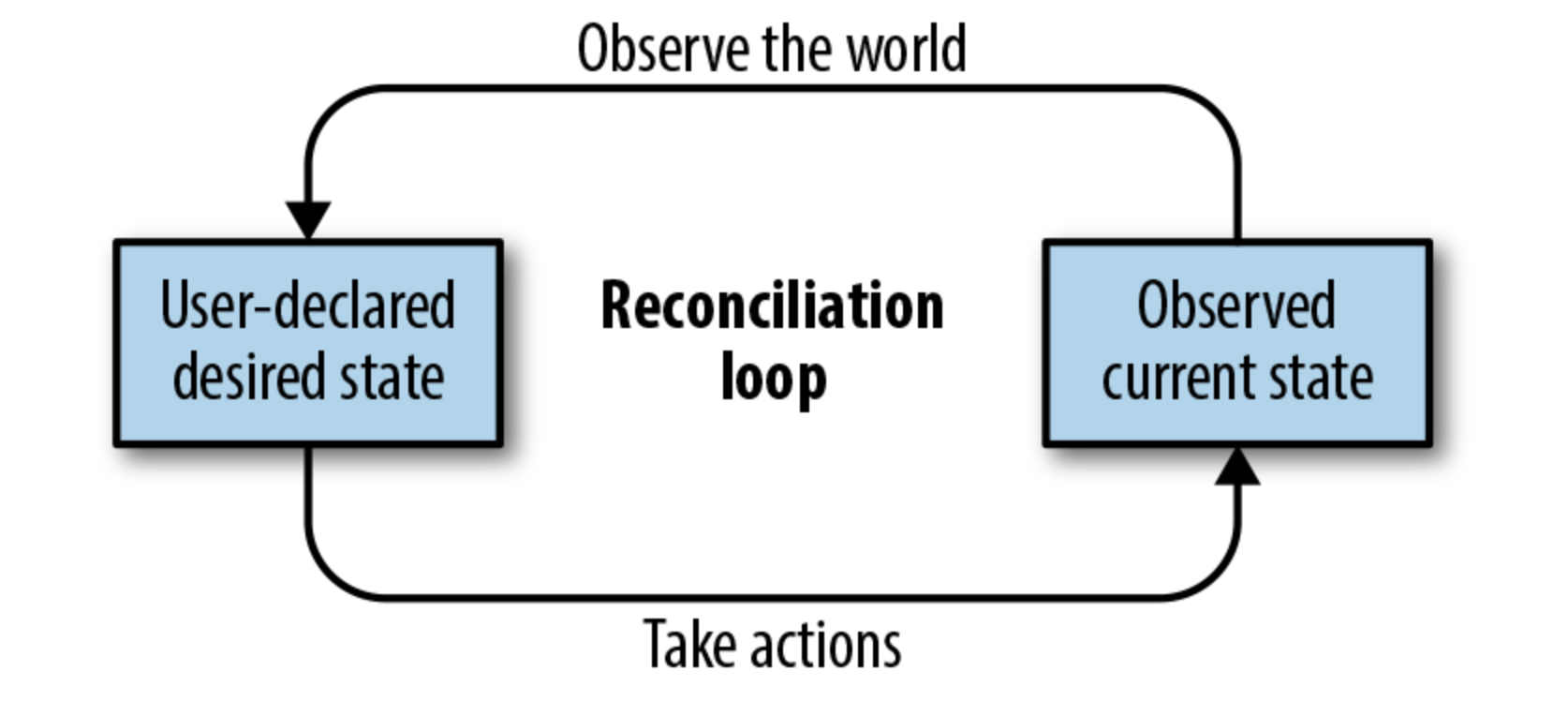
At the heart of an operator is a Kubernetes controller resource. This controller is a software loop which runs continually in the Kubernetes control plane and monitors specified Kubernetes object(s). It audits the current running state of the specified objects, and compares it to the user intended state of those objects (generally specified in YAML). If there are differences between the intended and current states, the controller will attempt modify objects to reach the intended (specified) state. This process is also referred to as a “reconciliation loop”.
Operators essentially create an application specific controller and a customer resource. This is enabled through the use of CRDs, which were initially introduced in Kubernetes 1.7. Kubernetes API extensions are then used to allow external systems (such as kubectl on a laptop) to interact with these custom objects as they would with a standard object, such as a Pod.
Overall, the architecture of a operator looks like this:
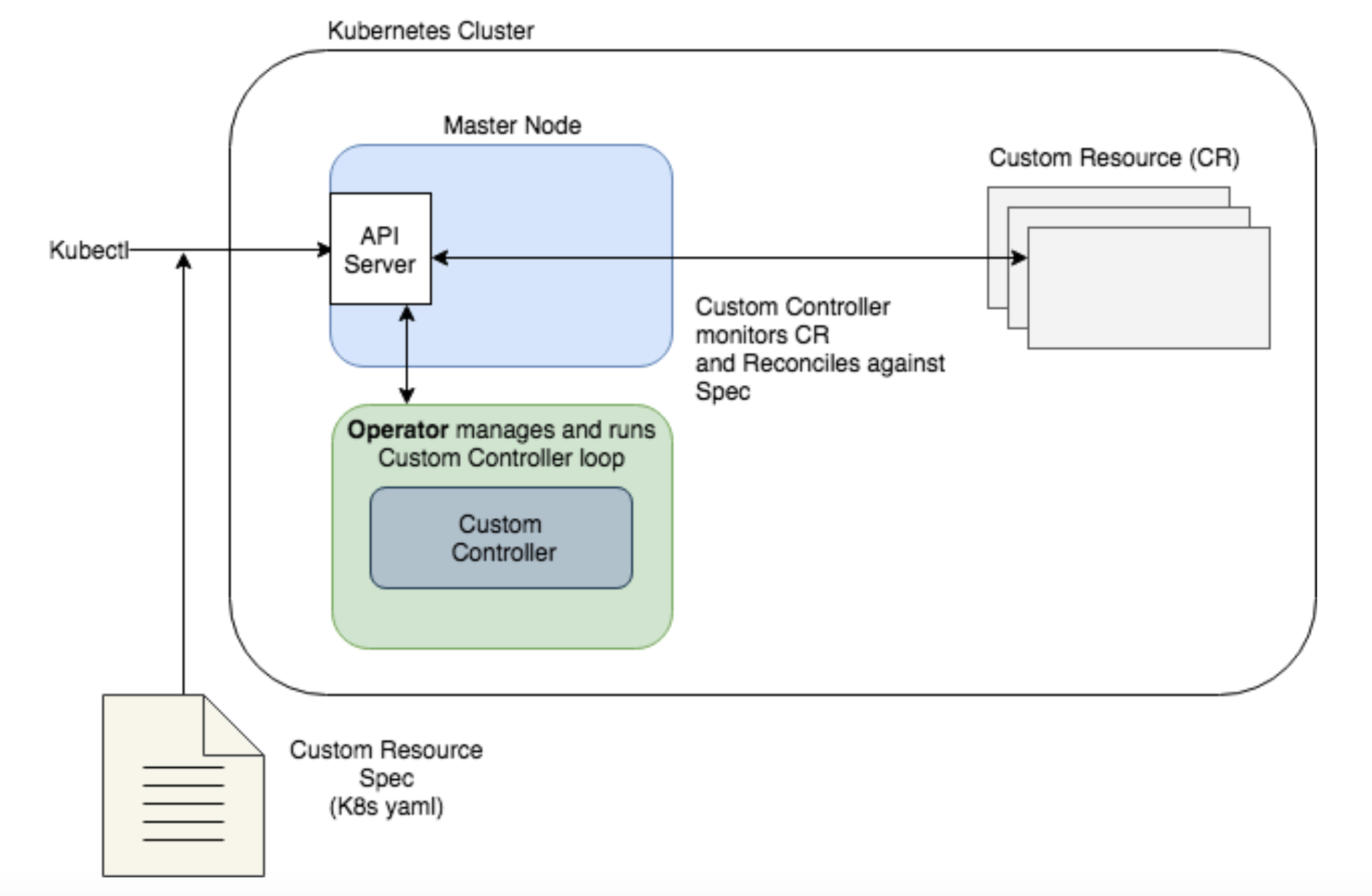
A catalog of available operators and additional information are available at operatorhub.io.
How do Helm and Operators Compare?
First and foremost: Helm charts and operators are not mutually exclusive. For example, an operator could be used to deploy and manage the lifecycle of the contents of a Helm chart. I prefer to view the two systems as different ways of addressing the complexity which comes with multi-component applications.
From a packaging perspective, it’s arguable that Helm and the Operator framework have more attributes in common than they do differences. Both allow for parametrized deployments, and have available application repositories (helm and operators respectively). Additionally, both methods will support custom lifecycles, be capable of installing dependencies, and forego an in cluster deployment component (Tiller) once Helm 3 is generally available.
The differences between the two can be framed in terms of their participation in Day 2 tasks. Operators make use of extensions to the Kubernetes cluster itself through the use of CRDs and API extensions. These custom objects become part of the Kubernetes resource hierarchy itself and can be interacted with like any other Kubernetes primitive. Helm charts are instead deployed and viewed as a collection of Kubernetes resources built on top of the existing resource types. The operational lifecycles of these applications is handled outside of Kubernetes itself. Their “reconciliation loops” will need to be managed by other tools and processes.
Which of these options is more appropriate for a use case will likely depend on the roles and responsibilities of the people and team(s) involved. If the application and Kubernetes cluster operators are the same, or have some overlap, then Operators may have more appeal. The unification of Day 0 and 2 operations in a single interface can be powerful. However, if application and platform responsibilities lie with different groups, the relative simplicity of Helm charts as a deployment package may be preferable.
As Kubernetes continues to grow in popularity and reach this topic will only become more relevant to the day-to-day operations of the platform and the applications deployed on top of it. I expect both methods will continue to evolve and adopt additional functionality as the ecosystem around them matures. As always, please reach out to myself or the team to continue the conversation.